
In the era where fake news is the new news, everybody seems to be constantly seeking for (their version of) “truth”, or “fact”. It is quite ironic that while we are living in a world where information is more accessible than ever, we are less “informed” than ever. However, today, let’s take a break from all the chaos in real life and see if we can learn something about “truth” from the scientific world.
3 years ago, I spent my summer interning at a laboratory on social psychology, where I was exposed, for the very first time, to statistics and the scientific methodology. That was also when my naive image of “science” shattered. It was not noble as I thought, but, as real life, messy and complicated. My colleagues showed me the dark corners of psychology research, where people are willing to do whatever it takes to have a perfect p-value and get their paper published (for example, the scandal of Harvard professor of psychology Marc Hauser). If you are somebody working in the science world, you must not be so surprised: social science, and psychology in particular, is plagued with misconduct and fraud. Reproducibility is a huge problem, as proved by the reproducibility project, where 100 psychological findings were subjected to replication attempts. The results of this project were less than a ringing endorsement of research in the field: of the expected 89 replications, only 37 were obtained and the average size of the effects fell dramatically. At the end of the internship, I wrote an article with the title “Is psychology a science ?”, where I stated in my conclusion “Pyschology remains a young field in search for a solid theoretical base, but that can not justify for the lack of rigor in the research method. Science is about truth and not about being able to publish.”
“Science is about truth”.
Is it ?
This seemingly evident statement came back to hunt me 3 years later, when I came across this quote by Neil deGrasse Tyson, a scientist that I respect a lot:
The good thing about science is that it’s true whether or not you believe in it.
That was his answer for the question “What do you think about the people who don’t believe in evolution ?”.
If we put it in the context, where he already commented on the scientific method, this phrase becomes less troubling. However, I still find it very extreme and even misleading for layman people, just like my statement 3 years ago.
For me, science is about skepticism. It is more about not being wrong than being true. A scientific theory never aspires to be “final “, it will always be subject to additional testing.
To better understand this statement, we need to go back to the root of the scientific method: statistics.
Let’s take an example in clinical trial: supposing that you want to test a new drug. You find a group of patients, give half of them the new drug and the rest a placebo. You measure the effect in each group and compare if the difference between those 2 groups is significant or not by using a hypothesis test.
This is where the famously misunderstood p-value comes into play. It is the probability, under the assumption that there is no true effect or no difference, of collecting data that shows a difference equal to or greater than what we observed. For many people (including researchers), this definition is very counter-intuitive because it does not do what they are expecting: p-value is not a measure about the effect size, it does not tell you how right you are or how big is the difference, it just shows you a level of skepticism. A small p-value simply states that we are quite surprised with the difference between 2 groups, given that we are not expecting it. It is only a probability, so if someone try a lot of hypothesis on the data, eventually they will get something significant (this is what known as the problem of multiple comparisons, or p-hacking).

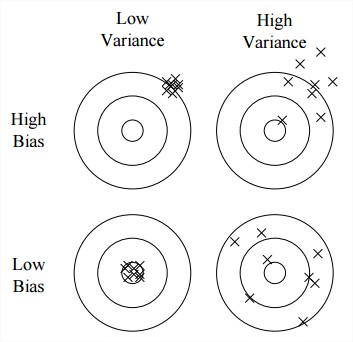
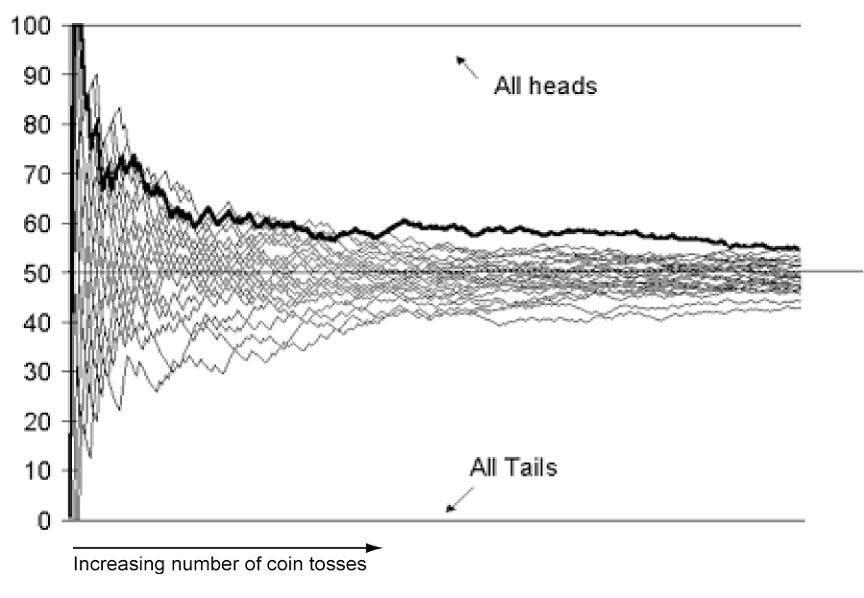
The whole world of research is driven by this metric. For many journals, a p-value less than 5% is the first criteria for a paper to be reviewed. However, things are more complicated than that. As I mentioned earlier, p-value is about statistical significance, not practical significance. If a researcher collects enough data, he will eventually be able to lower the p-value and “discover” something, even if the scope of it is extremely tiny that it doesn’t make any impact in real life. This is where we need to discuss about the effect size and more importantly, the power of a hypothesis test. The former, as it names suggests, is the size of the difference that we are measuring. The latter is the probability that a hypothesis test will yield a statistically significant outcome. It depends on the effect size and the sample size. If we have a large sample size and want to measure a reasonable effect size, the power of the test will be high and vice versa, if we don’t have enough data but aim for a small effect size, the power will be low, which is quite logical: we can’t detect a subtle difference if we don’t have enough data. We can’t just throw a coin 10 time and said that because there are 6 heads, the coin must be biased.
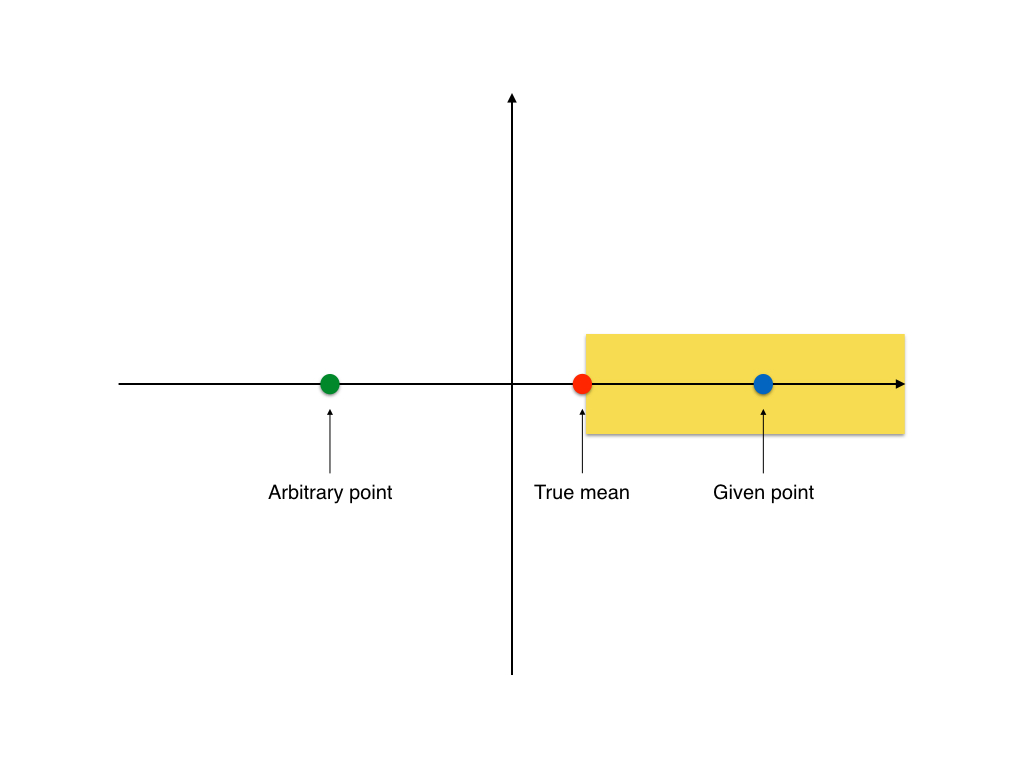
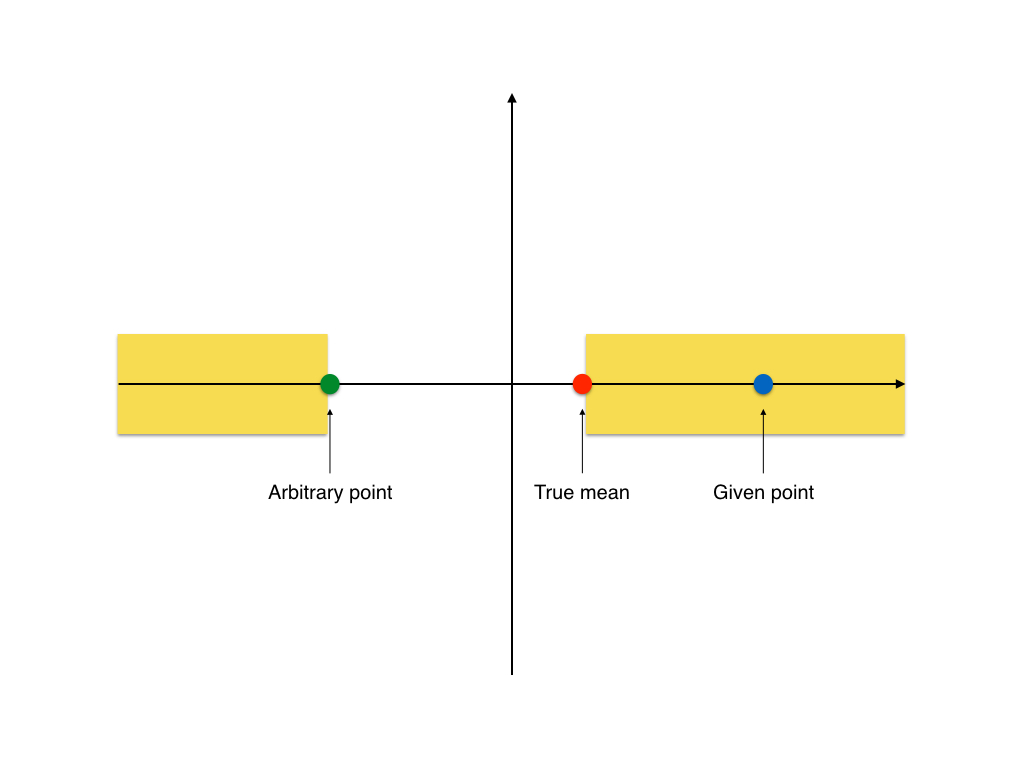
In fields where experiments are costly (social science, pharmaceutical,…), the small sample size led to a big problem of truth inflation (or type M error). This is when the hypothesis test has a weak power and thus can’t detect any reliable difference.
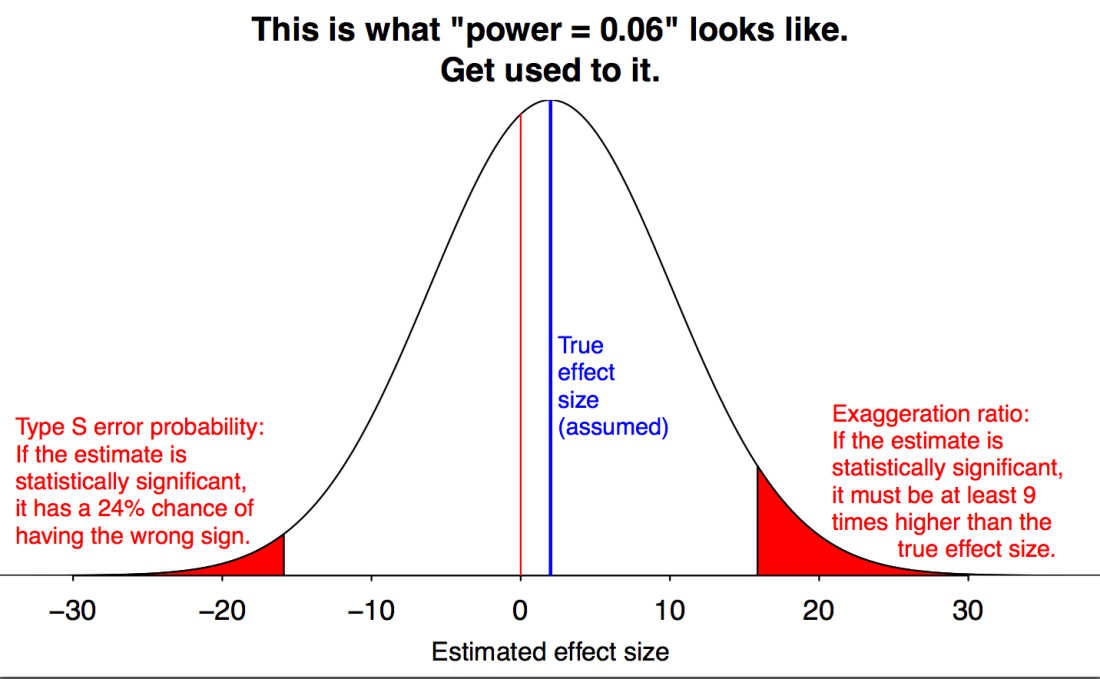
In the curve above, we see that our data needs to have an effect size 9 times greater than the actual effect size to be statistically significant.
The truth inflation problem turns out to be quite “convenient” for researchers: they get a significant result with a huge effect size! This is also what the journals are looking for: “groundbreaking” results (large effect size result in some research field with little prior research). And it is not rare.
All these discussions is to show you that scientific methodology is not definite. It is based on statistics, and statistics is all about uncertainty, and sometimes it gets very tricky to do it the right way. But it needs to be done right. Some days it is hard, some days it is nearly impossible, but that’s the way science works.

To conclude, I think that science is not solely about truth, but about evaluating observations. This is where we can go back to the real world: in this era where we are drowning in data, we also need to have a rigorous approach to process them: cross-check the information from multiple sources, be as skeptical as possible to avoid selection bias, try not to be wrong and most importantly, be honest to one self, because at the end of the day, truth is a subjective term.



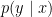 . In classification task, these models search a hyperplane (a decision boundary) seperating different classes. The majority of popular algorithms belongs to this family: logistic regression, svm, neural net, … On the other hand, Generative methods model
. In classification task, these models search a hyperplane (a decision boundary) seperating different classes. The majority of popular algorithms belongs to this family: logistic regression, svm, neural net, … On the other hand, Generative methods model  (and
(and 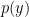 ). This means that it will give us a probability distribution for each class in the classification problem. This give us an idea of how the data is generated. This type of model relies heavily on Bayes rule to update the prior and derive the posterior. Some well-known examples are Naive Bayes, Gaussian Discriminant Analysis, …
). This means that it will give us a probability distribution for each class in the classification problem. This give us an idea of how the data is generated. This type of model relies heavily on Bayes rule to update the prior and derive the posterior. Some well-known examples are Naive Bayes, Gaussian Discriminant Analysis, …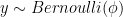


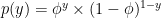
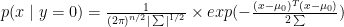


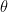 is some function of of
is some function of of 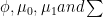 .
.


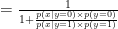
 :
:

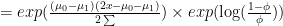


![= exp[ (\log(\frac{1-\phi}{\phi}) - \frac{\mu_0^2 + \mu_1^2}{2\sum}) \times x_0 + \frac{\mu_0 - \mu_1}{\sum} \times x ]](https://s0.wp.com/latex.php?latex=%3D+exp%5B+%28%5Clog%28%5Cfrac%7B1-%5Cphi%7D%7B%5Cphi%7D%29+-+%5Cfrac%7B%5Cmu_0%5E2+%2B+%5Cmu_1%5E2%7D%7B2%5Csum%7D%29+%5Ctimes+x_0+%2B+%5Cfrac%7B%5Cmu_0+-+%5Cmu_1%7D%7B%5Csum%7D+%5Ctimes+x+%5D&bg=ffffff&fg=000000&s=0&c=20201002)
 so that we can have the desired form
so that we can have the desired form  . The former equation is then:
. The former equation is then:![\frac{1}{1 + \frac{p(x \mid y=0) \times p(y=0)}{p(x \mid y=1) \times p(y=1)}} = \frac{1}{1 +exp[ (\log(\frac{1-\phi}{\phi}) - \frac{\mu_0^2 + \mu_1^2}{2\sum}) \times x_0 + \frac{\mu_0 - \mu_1}{\sum} \times x ] }](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B1+%2B+%5Cfrac%7Bp%28x+%5Cmid+y%3D0%29+%5Ctimes+p%28y%3D0%29%7D%7Bp%28x+%5Cmid+y%3D1%29+%5Ctimes+p%28y%3D1%29%7D%7D%C2%A0%3D+%5Cfrac%7B1%7D%7B1+%2Bexp%5B+%28%5Clog%28%5Cfrac%7B1-%5Cphi%7D%7B%5Cphi%7D%29+-+%5Cfrac%7B%5Cmu_0%5E2+%2B+%5Cmu_1%5E2%7D%7B2%5Csum%7D%29+%5Ctimes+x_0+%2B+%5Cfrac%7B%5Cmu_0+-+%5Cmu_1%7D%7B%5Csum%7D+%5Ctimes+x+%5D+%7D&bg=ffffff&fg=000000&s=0&c=20201002)
 is:
is: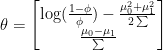
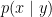 is mutlivariate gaussian. This observation shows us that GDA has a much stronger assumption than Logistic Regression. In fact, we can go 1 step further and prove that if
is mutlivariate gaussian. This observation shows us that GDA has a much stronger assumption than Logistic Regression. In fact, we can go 1 step further and prove that if 





 (or adjusted
(or adjusted  ) quantifies how well the model predicts the Y values. If the goal is to understand how the various X variables impact Y, then multicollinearity is a big problem.
) quantifies how well the model predicts the Y values. If the goal is to understand how the various X variables impact Y, then multicollinearity is a big problem.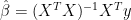
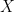 is not full rank (ie. the predictors are not independent from each other),
is not full rank (ie. the predictors are not independent from each other), 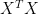 is not invertible, and thus there is no unique solution for
is not invertible, and thus there is no unique solution for 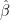 . This is where all the troubles begin. One problem is that the individual P-values can be misleading (a P-value can be high, even though the variable is important). The second problem is that the confidence intervals on the regression coefficients will be very wide. The confidence intervals may even include zero, which means one can’t even be confident whether an increase in the X value is associated with an increase, or a decrease, in Y. Because the confidence intervals are so wide, excluding a subject (or adding a new one) can change the coefficients dramatically and may even change their signs.
. This is where all the troubles begin. One problem is that the individual P-values can be misleading (a P-value can be high, even though the variable is important). The second problem is that the confidence intervals on the regression coefficients will be very wide. The confidence intervals may even include zero, which means one can’t even be confident whether an increase in the X value is associated with an increase, or a decrease, in Y. Because the confidence intervals are so wide, excluding a subject (or adding a new one) can change the coefficients dramatically and may even change their signs. , but the coefficient t-tests are non-significant, which suggest that none of the two predictors are significantly associated to
, but the coefficient t-tests are non-significant, which suggest that none of the two predictors are significantly associated to 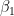 and
and 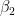 are 2 the estimated coefficients,
are 2 the estimated coefficients, 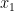 given
given 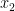 is already in the model and vice versa,
is already in the model and vice versa, 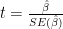 ). This means that the power of the hypothesis test—the probability of correctly detecting a non-zero coefficient—is reduced by collinearity: a predictor with a small coefficient might be “masked”, even if it is statistically significant.
). This means that the power of the hypothesis test—the probability of correctly detecting a non-zero coefficient—is reduced by collinearity: a predictor with a small coefficient might be “masked”, even if it is statistically significant.
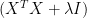 is always invertible; thus, there is always a unique solution
is always invertible; thus, there is always a unique solution  .
.  to penalize large coefficients. Being a biased estimator, it trades some degree of bias to reduce the variance, and therefore results in more stable estimates.
to penalize large coefficients. Being a biased estimator, it trades some degree of bias to reduce the variance, and therefore results in more stable estimates.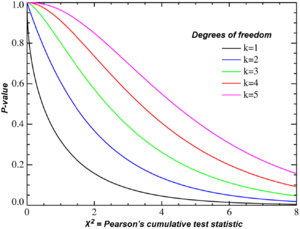
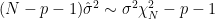
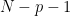 degrees of freedom, with
degrees of freedom, with 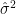 an unbiased estimate of
an unbiased estimate of 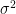 .
.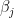 .
.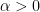 , the gamma function
, the gamma function 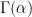 is defined by:
is defined by: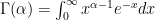
 , we have:
, we have: 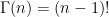 .
. if
if 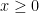
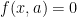 otherwise.
otherwise. . The gamma function implies that:
. The gamma function implies that: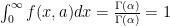
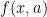 satisfies the 2 basic properties of a probability distribution function.
satisfies the 2 basic properties of a probability distribution function.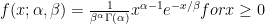
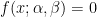 otherwise
otherwise and
and  are positive. The standard Gamma distribution has
are positive. The standard Gamma distribution has 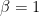 , so the pdf of a standard gamma is given by the
, so the pdf of a standard gamma is given by the 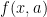 given above.
given above. be a positive integer. Then a random variable
be a positive integer. Then a random variable  is said to have a chi-squared distribution with parameter
is said to have a chi-squared distribution with parameter 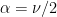 and
and 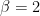 . The pdf of a chi-squared rv is thus:
. The pdf of a chi-squared rv is thus: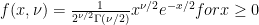
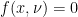 otherwise
otherwise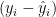 follow a normal distribution, thus to model the variance of X, which is the sum of the square of these values, we use a chi-square distribution.
follow a normal distribution, thus to model the variance of X, which is the sum of the square of these values, we use a chi-square distribution.